Scraping entire text & keywords from the webpage with help of newspaper & nltk || Python
I'm using the newspaper and nltk library for scraping, summarizing & converting articles from a webpage to a text file.
Here the tokenizer "punkt" is used for splitting a phrase, sentence, paragraph, into smaller units, such as individual words or terms.
#importing libraries
from newspaper import Article
import nltk
#create tokenizer
nltk.download('punkt')
#input-website and create object for article
url= 'https://www.marketwatch.com/'
article = Article(url, language="en")
#downloading/parsing/npl the article
article.download()
article.parse()
article.nlp()
#printing the scraped>processed data
print("Article Title:")
print(article.title) #prints the title of the article
print("\n")
print("Article Text:")
print(article.text) #prints the entire text of the article
print("\n")
print("Article Summary:")
print(article.summary) #prints the summary of the article
print("\n")
print("Article Keywords:")
print(article.keywords) #prints the keywords of the article

#creating text file and adding data to it.
file1=open("NewsFile.txt", "w+")
file1.write("Title:\n")
file1.write(article.title)
file1.write("\n\nArticle Text:\n")
file1.write(article.text)
file1.write("\n\nArticle Summary:\n")
file1.write(article.summary)
file1.write("\n\n\nArticle Keywords:\n")
keywords='\n'.join(article.keywords)
file1.write(keywords)
file1.close()
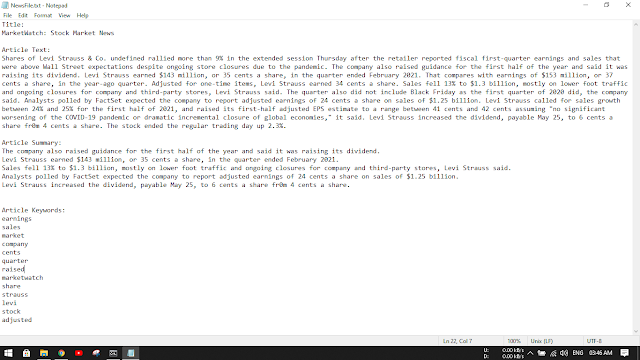
we will get Title, Text, summary, and keywords in the text file.
You can later word wrap the data in the text file to get a proper view of it.


Comments
Post a Comment